

The problem with unstructured documents
Any information that is not stored in a database or in a spreadsheet is unstructured. Many of these documents contain valuable data but since the data does not follow an organized format, it is difficult to search for information or use it to drive business insight. Examples in healthcare are physician notes, prescription information, discharge notes, emails, and other clinical documents.
Gartner insights say that 80% of enterprise data is unstructured.
Gartner insights say that 80% of enterprise data is unstructured. This translates to either a loss of invaluable information or manual hours spent trying to convert part of this unstructured information into electronic documents and digital files. Many organizations may outsource to BPOs who either have a large labor force to do it manually or may themselves invest in AI technology for intelligent document processing.
Picture this scenario – in financial operations, there is a large volume of accounts receivable and accounts payable. There is no single standard format used to transfer this information from one organization to another. This means that with hundreds of buyers and sellers involved in various commercial transactions, there is a need to digitize and re-digitize information flowing in to suit different storage formats. What it often boils down to is manual input of data by punching the keyboards to create a data file that can then be processed by ERP systems. If this could also be automated, time and cost savings will be the end result.
AI technology and Digital Document Management
Document digitization using OCR (optical character recognition) has been around for some time. OCR technology can recognize text from scanned images. Examples of OCR we may be familiar with are PDF to text converters and also Google’s Image Search Function.
However, OCR technology is not foolproof. It is not 100% accurate because text can be misread. OCR also works better with typewritten text and not so well with handwritten documents and it does not possess the human ability to make an educated guess when it comes across scanned documents that may have blurry areas.
If you need a 99% accuracy in document digitalization then AI and machine learning technology needs to be integrated with OCR technology. Intelligent document processing using AI will speed up data extraction and conversion while also improving accuracy.
Hundreds of documents can be processed in one minute compared to one document in ten minutes.
The 3 ways AI is improving document processing
When developers integrate AI into scanning tools it will do away with the manual filing of scanned documents. For instance, DocExtract, the proprietary software developed by iTech, uses machine learning and annotation tools to convert documents into searchable digital files that are stored in large document storage systems. Here is more that it can do.
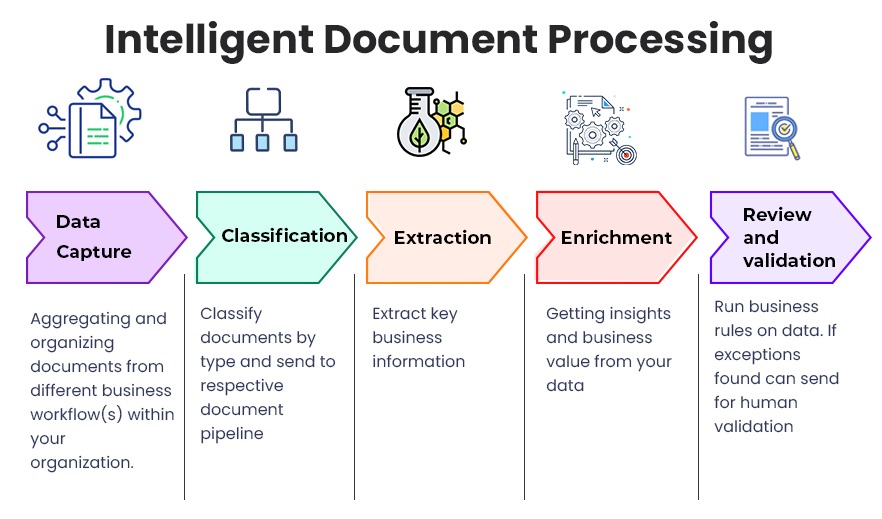
1. Automating document generation
Optical character recognition when converting unstructured or physical documents into electronic documents requires manual verification before saving them in the document management system. This slowed down the whole process.
With AI and natural language processing (NLP), OCR technology becomes much more advanced. Now it will not only more accurately convert into digital documents but with AI, documents can also be grouped and classified by topics or keywords based on predefined formulae. It saves time instead of having to manually sort and store electronic documents. More on this in the third point.
2. NLP combined with OCR for data extraction
Let me explain this using the healthcare scenario. Pathology and imaging reports contain important clinical data and numerical values in free-text narratives. The current approach for processing scanned EHR documents often involves OCR and very rarely are Natural Language Processing models attempted.
OCR extracts words from the scanned images by the process of segmentation. In this process word lines, words and characters are isolated from the background image to extract machine-readable text. This is pre-processing of documents.
After OCR is completed, iTech’s DocExtract uses NLP in post-processing. This will identify OCR mistakes by understanding context which OCR on its own cannot. Further, if data is not readily available, missing, not in the right place or text is not legible, OCR will usually ignore the information, However, with data capture automation, such exceptions are either automatically handled or can be moved to human processing for further inputs and this leads to higher accuracy.
3. Categorizing different types of documents
Organizations are continually collecting documents from different sources. AI and machine learning algorithms can identify similarities between data collected from different documents and treat them differently. For instance, it recognizes content in an invoice and treats it differently from data collected from a patient report. The trained models in intelligent document processing, analyze documents that can contain rich components such as graphs and charts and extract data and classify and digitally display the information. This includes addresses, contact details, invoices, employee and customer details.
The best part of AI-powered machine learning is that the algorithms learn through experience.
Research by PwC found that even rudimentary AI-based data extraction can save businesses 30%-40% of hours that are usually spent on such processes.
iTech’s DocExtract is proprietary document digitalizing software developed through 10 years of experience in handling document data services for companies in the USA and globally. We have scanned millions of documents and images in this time. While we don’t sacrifice quality, you don’t have to break the bank when you choose DocExtract’s paper-to-document digitization conversion services. Schedule a demo with us to know more.

Biju Narayanan
Biju is an emphatic people management leader and works by the vision that change is the door to new opportunities and innovation. As Director, he has been guiding iTech on a path of innovation for over 19 years. iTech is a full-service custom software company with a large portfolio of successful domestic and international projects including Fortune 500 organizations. Biju specializes in the healthcare, sports and logistics industries with particular focus on AI and ML. Outside of work, you may find him hitting a lethal jump smash on the badminton court and he is also a creative artist.







