

In the field of legal technology, there has been a notable absence of specialized software for immigration attorneys. Traditionally, legal software has primarily focused on case management and form creation, leaving a significant gap in the market for tools designed to cater specifically to the needs of American immigration lawyers.
Now, a new AI-driven platform has emerged to fill this void in the field of US immigration software. Developed by iTech, this platform represents a notable advancement in the legal software industry. Unlike conventional solutions, it leverages artificial intelligence and machine learning to proactively identify legal issues and craft tailored briefs for immigration attorneys.
The Need for Specialized US Immigration Software
The need for such a solution arises from the constantly evolving landscape of immigration law. With shifting regulations and policies, immigration attorneys face unique challenges that demand specialized software. For example, each year, the U.S. President and Congress decide on the numerical limit for refugee admissions, and staying on top of these changes can be a daunting task for legal professionals.
USCIS (United States Citizen and Immigration Services) approves over 200,000 visa petitions every year but the H-1B visa cap each year is 65,000 with an additional 20,000 for those with a master’s degree from an American institution. This is the reason why software for immigration law firms is using Artificial Intelligence in visa research to analyse which factors can predict success.
Through a partnership with Velie Law Firm, iTech has brought together its expertise in AI and machine learning with Velie’s deep understanding of immigration law. This collaboration has resulted in a practical and highly effective solution for full-service US immigration software, providing valuable support to immigration attorneys. By analyzing historical case data, it empowers legal professionals to address potential challenges and enhance their success rates. This software for immigration attorneys represents a significant advancement in the legal tech industry, offering a much-needed and efficient tool for those practicing immigration law.
Benefits of AI in H-1B Visa process
While AI in law processes has numerous applications, it is proving its value in the field of immigration law.
iTech has developed AI software for solutions for full-service immigration law firms and US immigration attorneys to analyze vast amounts of case data to arrive at scenarios that have the probability of success.
The H-1B visa process requires the employer (also known as the sponsorship company) to pay the application process fee. Typically, apart from the application fee, there are also legal costs added on. The estimated cost for a single visa petition can be up to $7000. Predictive analytics in law, therefore, is an important part of ensuring that the application meets all requirements.
iTech has developed AI solutions for full-service immigration law firms and immigration attorneys to analyze vast amounts of case data to arrive at scenarios that have the probability of success.
The benefits of using AI-powered immigration software for attorneys
- Due diligence can account for up to 50% of legal costs.
- The time taken on document review can fall by as much as 80% when Machine Learning is used to review concurrence
- This is because ML algorithms are much faster than humans at processing documents and producing more efficient outputs that can be validated against statistical data.
AI in US immigration software
Artificial intelligence in legal practice is no longer an unknown frontier yet to be crossed. AI in law has many applications, particularly in document processing. When Ml and AI applications are properly built and deployed it provides attorneys with speedy insights to make informed data-driven decisions.
AI and Ml are often used interchangeably but there is a difference. For instance, if you have ever used Alexa or Siri (who hasn’t?) then that is AI in action. Artificial intelligence is the capability of making machines mimic human cognitive functions to give them the ability to problem-solve. AI mimics human powers of deduction and is the term used when a machine is able to accomplish tasks that normally require human intervention.
Machine Learning is based on the fact that machines can learn from statistical data to identify patterns and make decisions. Machine learning is a subfield of AI (the other is deep learning and NLP) that works on mathematical data models. Machine learning algorithms drive the applications used to build a series of automated tasks that can be either supervised or unsupervised – the difference lies if a human is involved in task completion or not. The system can also “learn” from data and progressively improve performance.
In legal practices where the risk of inaccuracies and exception handling can be relatively high, oftentimes supervised machine learning offers the safer route to faster research and instant access to data, accompanied by low risk.
Deep Learning uses ML techniques but requires massive data sets to train itself on. It uses neural networks i.e. it creates similar patterns as the human brain to solve problems. They can recognize numerical patterns from vectors such as images, sound and text. Neural networks can take raw data and classify them based on the training datasets. Every unit is called a “neuron” and there are a number of such artificial neurons in each activation layer. This introduces a non-linearity and multi-level layers into the activation function allowing for more depth and hence more accuracy. In short, deep learning’s neural networks can adapt to changing input data without the need for human intervention.
Natural Language Processing (NLP) is another AI process that allows computers to analyze and service meaning from human language, either verbal or from documents. AI in software for immigration lawyers always uses NLP because it means large amounts of research files and related data can be queried using legal terminology.
How machine learning algorithms work in visa applications software for immigration lawyers
It is possible to predict the outcomes of visa applications based on the applicant’s attributes run against data models. To create an effective data model, training data sets are part of the prerequisite. The norm is to train algorithms on 80% of the cleaned dataset and test against the remaining 20% of untouched data.
The Office of Foreign Labor Certification (OFLC) generates data about H-1B visas and millions of records can be anonymized for creating accurate training data sets. There are over 2 million data points covering the different statuses such as Certified, Denied, Pending Quality, Compliance review, etc.
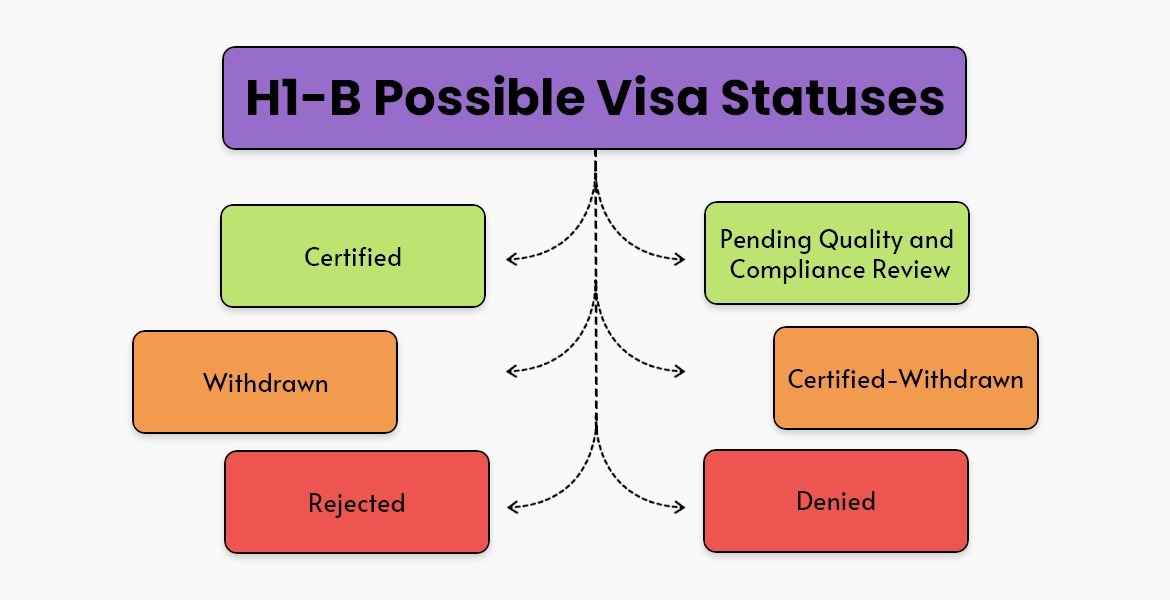
The success of the Machine Learning models is dependent on the data selection and extraction process along with Feature Engineering. There are different variables that need to be considered when it comes specifically to immigration software for attorneys. For example, wage categories and industry type as well as job functions. Feature engineering is the tricky part since it needs to prevent bias since systems are trained on data sets and success depends on ensuring datasets capture all patterns to prevent unconscious bias.
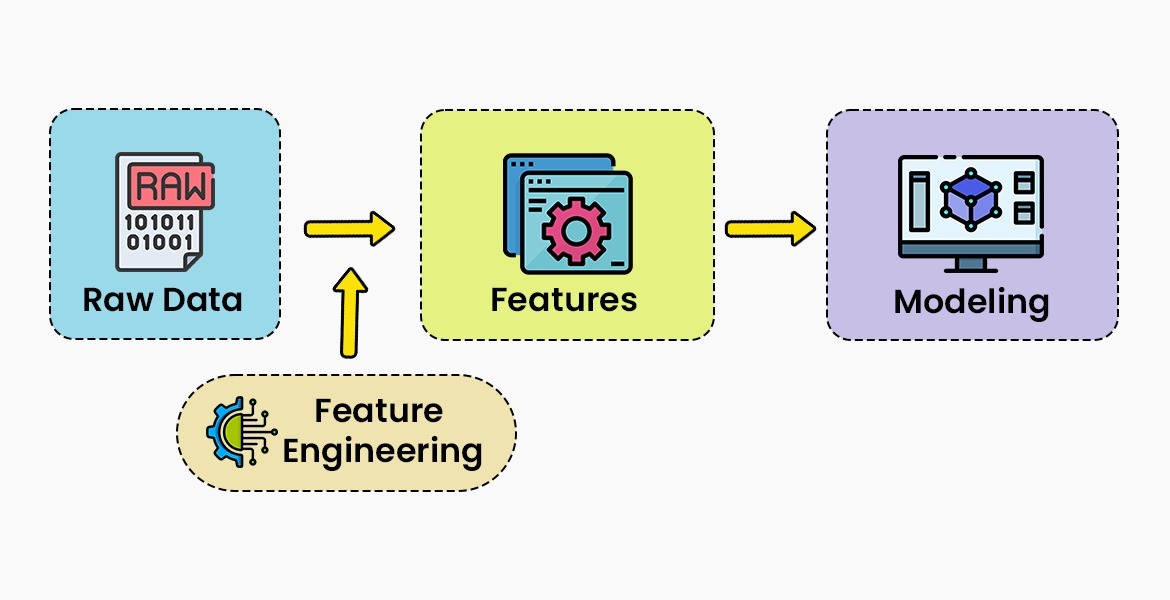
Feature engineering is crucial as it creates new features from the raw data using mathematical functions and adding predictive analytics to the ML algorithms.
Automated Document Parsing
With the model in place, the next step in iTech’s application comes into play i.e. automated document parsing. W have made life easier for attorneys by automating the document identification, indexing, and parsing of documents provided by petitioners and beneficiaries. The application uses Machine Learning techniques to extract the key fields from immigration forms. ML reduces manual effort and increases the accuracy of data input into the various systems. This allows the legal team to take action faster on the client’s behalf.
It is important here to understand the difference between OCR and Machine Learning digitalization. Optical Character Recognition or OCR works on a fixed layout, for example, it might be set to read documents in electronic formats, from specific coordinates or up to a specific text. However, modern ML algorithms use Natural Language Processing (NLP)and image classification to first identify the document type and then recognize what data needs to be extracted and match them to relevant fields as per the data model. This is then integrated into the analytics systems to get actionable insights.
Get Started
For more information on iTech’s intelligent document processing and Legal Analytics call us or message us here.






