

Considering that AI and ML applications are increasingly becoming a part of business operations, an important question pops up that cannot be ignored. Can machine learning models make mistakes? After all, ML models are meant to boost productivity, reduce errors, and mimic human decision-making. However, can it inadvertently replicate human inclinations for bias and errors? In simple terms, it can. This highlights the critical need to include an ML model monitoring framework in the development and deployment of reliable, impartial, and accountable AI applications.
What is Machine Learning Model Deployment?
Model deployment in machine learning refers to the process of taking a trained machine learning model (from the development environment) and making it available for use in a real-world, operational environment. This involves deploying the model to serve predictions or inferences based on new, incoming data.
Why is it important to include ML model monitoring after deployment?
Machine learning models can work accurately and exceed business expectations. However, mistakes might arise with time due to shifts in data patterns, unaccounted biases in training data, and unforeseen interactions with real-world inputs. These errors often occur when the model encounters data that it hasn’t seen before or when the model’s assumptions no longer hold in a changing environment. Continuous monitoring and adaptation are crucial to mitigate these issues.
Once you’ve deployed a machine learning model, it’s vital to keep a close watch on it. You should set up robust logging and monitoring systems to track how the model’s API is used, its performance, and any potential errors. For instance, monitor the types and formats of data sent to the API, ensuring it conforms to the model’s expectations.
Regular performance assessments help catch issues early, allowing you to make necessary adjustments. It’s also essential to ensure the model can adapt by seamlessly integrating new model versions and enhancing the API’s capacity to handle increased traffic. These proactive steps ensure that your machine learning model deployment is successful, consistently providing accurate predictions in real-world scenarios.
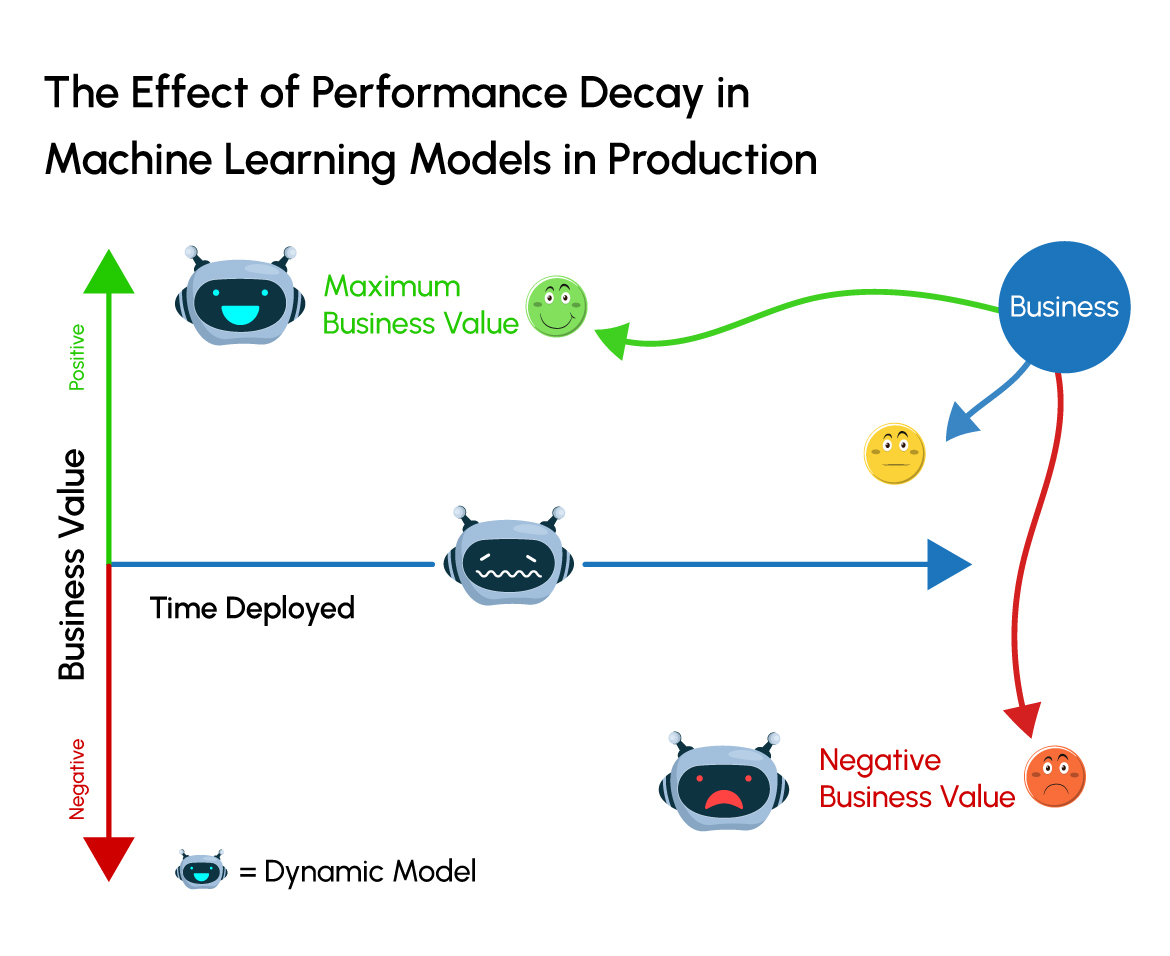
The goals for ML model monitoring are:
1. Detect problems with your model and the system serving your model in production before they start to generate negative business value.
2. Take action by triaging and troubleshooting models in production or the inputs and systems that enable them.
3. Ensure their predictions and results can be explained and reported.
4. Ensure the model’s prediction process is transparent to relevant stakeholders for proper governance.
5. Provide a path for maintaining and improving the model in production.
Key points to consider in ML model deployment?
Serving Infrastructure: Deployed models require a serving infrastructure that can handle incoming data, make predictions, and return results to applications or users. This infrastructure typically involves web servers or specialized inference services. It also includes API endpoints that allow applications to send data for prediction and receive the model’s output.
Scalability: Model deployment must accommodate varying workloads. It should be able to scale horizontally to handle increased traffic and maintain low-latency response times.
Model Format: Ensure that the model is in a suitable format for deployment, such as TensorFlow’s SavedModel or ONNX. This format should be optimized for inference and compatible with the deployment framework.
Data Drift: Continuously monitor the incoming data for data drift, which refers to changes in the statistical properties of the input data over time. Detecting data drift is important because it can impact the accuracy of the model’s predictions.
Are ML Production Environment and Deployment Environment synonymous?
The production environment and the deployment environment can be synonymous or closely related. However, there is a subtle distinction between the two, depending on how these terms are used in specific situations.
Production Environment: The production environment is where the live business operations occur. It encompasses the complete system, including applications, databases, and services. It serves customers and users, and any disruptions in this environment can have direct business impacts. It’s the context where the entire business operates.
Deployment Environment for ML: The deployment environment is a controlled, often isolated space within the production environment. It is dedicated to hosting, managing, and testing machine learning models. It allows for multiple versions of a model to coexist, facilitates testing, and ensures that model changes do not disrupt the entire production system.
The key difference is that the production environment is about the entire business operation, while the deployment environment is a specific part of the production environment focused on machine learning models.
What are the 2 levels of monitoring of ML Models?
Machine learning model monitoring serves two essential purposes: functional and operational monitoring.
Functional Monitoring of ML Models:
Functional monitoring extends beyond accuracy to include metrics such as precision, recall, F1 score in ML, and other metrics like the ROC curve (where a value of 1 indicates a perfect model). These metrics offer a more nuanced view of the model’s performance, which is crucial in scenarios where false positives or negatives have significant consequences. Additionally, functional monitoring establishes a continuous validation framework, periodically testing the model with diverse datasets to ensure its ability to generate reliable predictions remains consistent.
F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
What is the F1 score in machine learning? It is a metric used to assess the performance of a classification model. It combines two essential metrics, precision, and recall, into a single score. Precision measures the model’s ability to accurately classify positive instances, while recall gauges its ability to capture all actual positive instances. a decreasing F1 score over time can indicate that the model’s performance is deteriorating
Operational Monitoring:
Operational monitoring goes beyond tracking resource utilization, response time, and error rates. It encompasses a broader range of system-level factors, including network latency, database query performance, and the scalability of the model-serving infrastructure. Anomaly detection systems are integral to operational monitoring, proactively identifying unusual patterns or outliers and facilitating prompt issue resolution to maintain the model’s integration within the production environment smoothly.
ML Model drift and Data drift are typically components of functional monitoring in machine learning.
Machine learning (ML) model drift and data drift are related concepts, but they refer to different aspects of model performance in a deployed environment:
1. What is Concept Drift or ML Model Drift
ML model drift, also known as concept drift, occurs when the relationship between the input features and the target variable (the concept the model is trying to learn) changes over time. This means that the assumptions made during model training are no longer valid. Model drift can result in a decrease in predictive accuracy as the model’s understanding of the underlying data distribution becomes outdated. Common causes of model drift include shifts in customer behavior, changes in market conditions, or evolving user preferences.
Understanding what is concept drift is easier with this example: consider a sentiment classification model that determines whether online content expresses positivity or negativity. In a world of ever-changing opinions, this model’s challenge lies in adapting to shifts in public sentiment over time. What was once tagged as positive may evolve into negativity in our highly opinionated social media landscape. “Sick” used to mean feeling unwell, but in informal slang, it can now also indicate something impressive or cool.
2. What is Data Drift monitoring
Data drift, on the other hand, is about changes in the input data used for making predictions. Data drift happens when the statistical properties of the input data, such as feature distributions, means, variances, or categorical feature proportions, evolve over time. What is data drift’s significance in ML model monitoring is that it recognizes that the incoming data differs significantly from the data the model was trained on. This will lead to a drop in the model’s accuracy because it may not be able to generalize well to these new data patterns.
Imagine a recommendation system for an e-commerce platform that suggests products to users based on their past preferences and browsing behavior. Over time, user preferences and behavior change due to evolving trends or seasonal shifts. This data drift can lead to a decline in recommendation accuracy as the model struggles to adapt to the changing preferences and behaviors of users.
To gain valuable insights into the power of continuous model monitoring and explainable AI, request a live demo with our AI experts. Discover how these cutting-edge technologies can transform your operations and decision-making.

Navin Kumar Parthiban
Navin Kumar Parthiban is a seasoned professional in the field of AI technologies and is a Director at iTech India. With a passion for innovation and a keen understanding of the ever-evolving landscape of artificial intelligence, Navin has played a pivotal role in driving iTech India’s success and technological advancements. Navin regularly shares his insights and knowledge through articles, seminars, and workshops. He believes in the power of AI to revolutionize industries and improve people’s lives, and he is dedicated to staying at the forefront of this rapidly evolving field.







